스트림(STREAM)이란?
stream은 iterator와 비슷한 역할을 하는 반복자
- 람다식으로 요소 처리 코드를 제공
- 내부 반복자를 사용하므로 병렬 처리가 쉽다
- 중간 처리와 최종 처리 작업을 수행
ITERATOR와 STREAM의 차이점
- iterator는 컬렉션의 요소를 가져오는 것부터 처리하는 것까지 개발자가 작성해야 함
- stream은 람다식으로 요소 처리 내용만 전달, 반복은 컬렉션 내부에서 일어난다.
콜렉션 / 배열 /숫자 범위 / 파일 / 디렉토리로부터 스트림 얻기
- 콜렉션
Stream<Student1> stream = studentList.stream();
stream.forEach(s-> System.out.println(s.getName()));- 배열
- 문자열로 구성된 배열일 경우,
String[] strArray = {"홍길동", "신용권", "김자바"};
Stream<String> strStream = Arrays.stream(strArray);- 숫자로 구성된 배열일 경우,
int[] intArray = {1, 2, 3, 4, 5};
IntStream intStream = Arrays.stream(intArray);
- 숫자 범위
1부터 100까지의 합 구하기
IntStream intStream = IntStream.rangeClosed(1, 100);
intStream.forEach(a->sum += a);- 파일
public class FromFIleContentExample {
public static void main(String[] args) throws IOException {
//해당 위치에 txt 파일 만들기
Path path = Paths.get("src/main/java/org/chapter16/linedata.txt");
Stream<String> stream;
//files.lines로 메소드 이용
stream= Files.lines(path, Charset.defaultCharset());
stream.forEach(System.out::println);
System.out.println();
//BufferedReader의 lines 메소드 이용
File file = path.toFile();
FileReader fileReader = new FileReader(file);
BufferedReader br = new BufferedReader(fileReader);
stream=br.lines();
stream.forEach(System.out::println);
}
}- 디렉토리
Path path = Paths.get("C:/tools/tomcat/apache-tomcat-9.0.71");
Stream<Path> stream = Files.list(path);
stream.forEach(p-> System.out.println(p.getFileName()));
중간 처리와 최종 처리
- 중간 처리 : 매핑, 필터링, 정렬 수행
- 최종 처리 : 반복, 카운팅, 평균, 총합 등 집계 처리 수행
+ 리덕션 : 대량의 데이터를 가공해서 축소하는 것
중간 처리와 최종 처리 차이점
- 리턴 타입이 스트림 : 중간 처리 메소드
- 리턴 타입이 기본 타입 또는 Optional이라면 최종 처리 메소드
종류
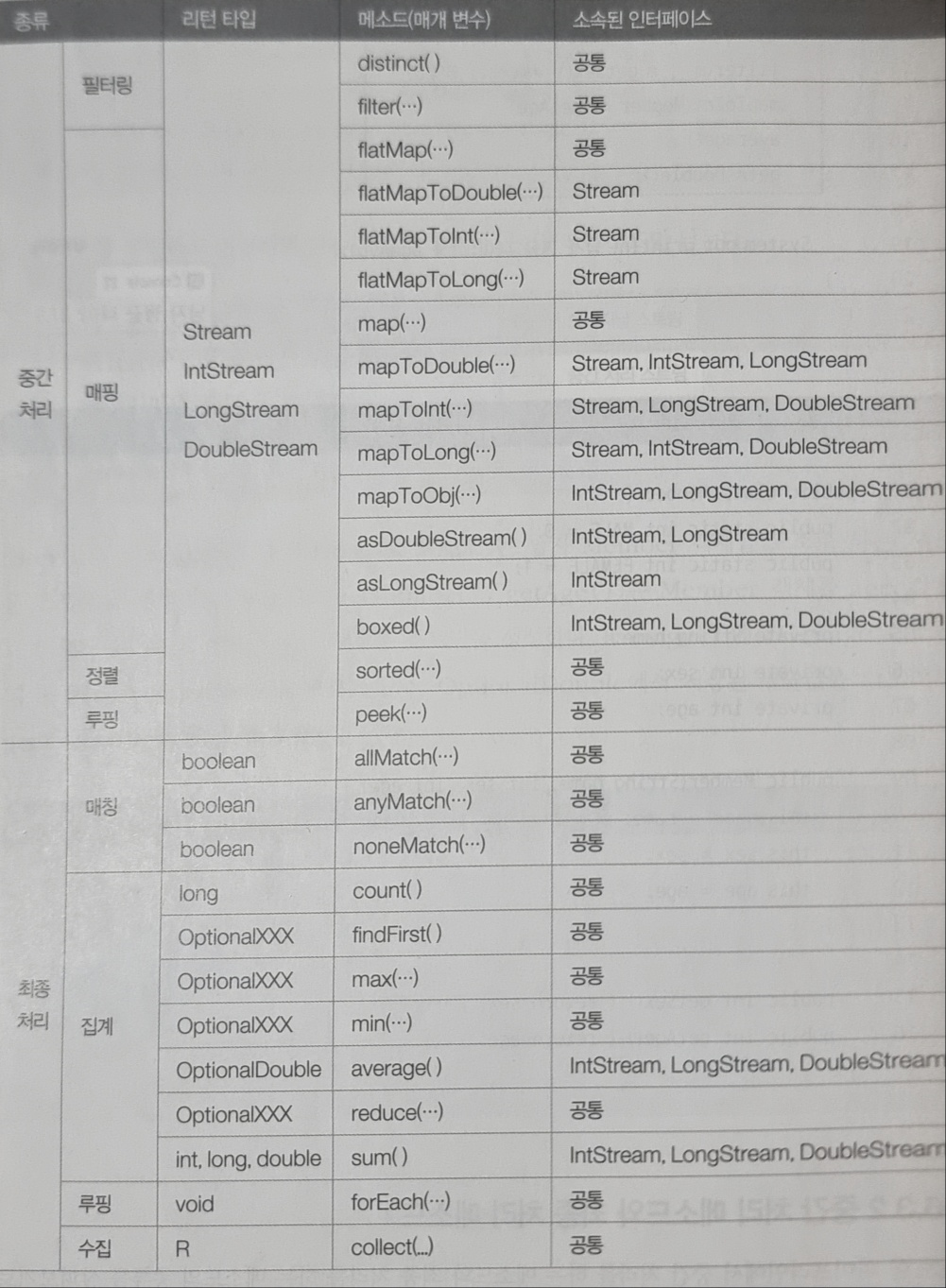
중간 / 최종 처리 메소드
• 필터링
- distinct() : 중복 제거
- filter() : 조건 필터링
• 매핑
- flatMapXXX()
- mapXXX()
- asXXXStream()
asDoubleStream(), asLongStream()
- boxed() : 중간 처리 단계에서 요소를 정렬해서 최종 처리 순서를 변경할 수 있도록 하는 것
• 루핑
- peek() : 중간 처리 메소드
- forEach() : 최종 처리 메소드
• 매칭
- allMatch()
- anuMatch()
- noneMatch()
• 기본 집계
- sum()
- count()
- average()
- max()
- min()
• Optional 클래스
- 집계 값을 저장할 수 있다.
- 기본 값(default)을 지정할 수 있다.
- 집계 값을 처리하는 Consumer를 등록할 수 있다.
• 커스텀 집계
- reduce()
stream에 전혀 값이 없을 경우, 디폴트 값이 identity 매개값 리턴
• 수집
- collect()
사용법 1 : 필터링 또는 매핑된 요소들을 새로운 컬렉션에 수집하고 이 컬렉션을 리턴한다.
사용법 2 : 사용자 정의 컨테이너에 수집하기
사용법 3 : 요소를 그룹핑해서 수집
사용법 4 : 그룹핑 후 매핑 및 집계
병렬 처리
병렬처리란 한 가지 작업을 서브 작업으로 나누고, 서브 작업들을 분리된 스레드에서 병렬적으로 처리하는 것을 말한다.
- 목적: 작업 처리 시간을 줄이는 것
- 자바 8부터 요소의 병렬 처리를 위한 병렬 스트림이 제공된다.
동시성과 병렬성
- 동시성: 멀티 작업을 위해 멀티 스레드가 번갈아가며 실행하는 성질
- 병렬성: 멀티 작업은 병렬적으로 실행되는 것처럼 보이지만, 사실 번갈아가며 실행하는 동시성 작업
1. 데이터 병렬성
: 데이터를 쪼개 서브 데이터로 만들고 서브 데이터를 병렬 처리하여 작업을 빨리 끝내는 것
2. 작업 병렬성
: 서로 다른 작업을 병렬 처리하는 것
병렬 스트림 생성
- parallelStream() : 컬렉션으로부터 병렬 스트림 바로 리턴
- parallel() : 순차 처리 스트림을 병렬 처리 스트림으로 변환해서 리턴
병렬 처리 성능
- 요소의 수와 요소당 처리 시간
(컬렉션 요소의 수가 적고 요소당 처리 속도가 짧으면 순차 처리가 병렬 처리보다 빠르다.
병렬 처리는 스레드품 생성, 스레드 생성이라는 추가 비용이 발생하기 때문)
- 스트림 소스의 종류
(인덱스로 요소를 관리하는 것들을 포크 단계에서 요소를 쉽게 분리할 수 있어 병렬 처리 시간이 절약된다. ArrayList나 배열보다 Set 요소들의 처리가 오래 걸린다. )
- 코어(Core)의 수
(싱글 코어 - 순차 처리가 빠름
코어의 수가 많을수록 - 병렬 처리가 빠름)
'백엔드' 카테고리의 다른 글
| 자바 기술 면접 대비 예상 질문 (1) | 2023.04.17 |
|---|---|
| [GITHUB] 생성한 프로젝트 깃허브에 올리기 (0) | 2023.04.12 |
| [이것이 자바다] chapter.16 확인 문제 (0) | 2023.04.11 |
| [자바 개념 정리] 컬렉션 프레임워크 (0) | 2023.04.04 |
| [이것이 자바다] chapter.15 확인 문제 (0) | 2023.04.04 |



