
교재 목차
Chapter11. 컬렉션 프레임웍
Chapter11. 컬렉션 프레임웍
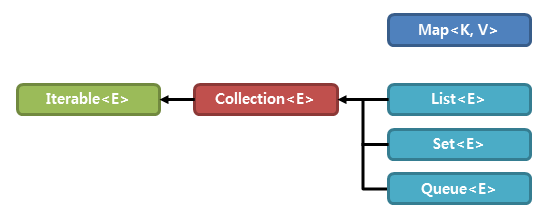
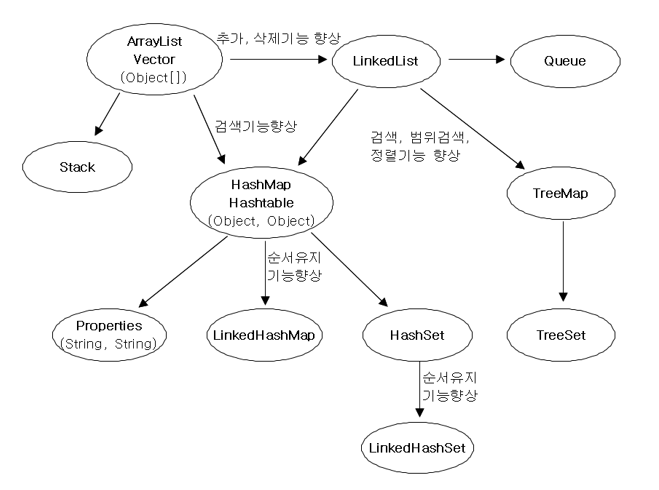
1. 컬렉션 프레임웍
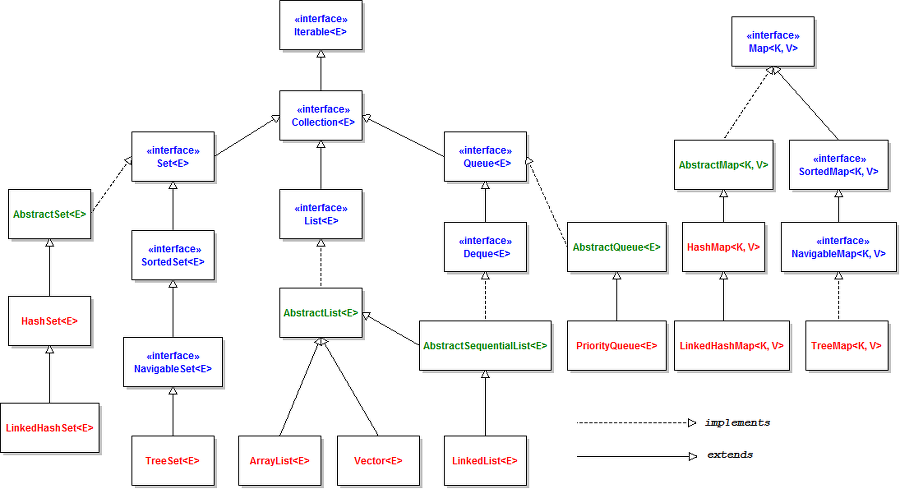
1-1. 컬렉션 프레임웍의 핵심 인터페이스


|
인터페이스
|
설명
|
구현 클래스
|
|
List<E>
|
순서가 있는 데이터의 집합으로, 데이터의 중복을 허용함.
|
Vector, ArrayList, LinkedList, Stack, Queue
|
|
Set<E>
|
순서가 없는 데이터의 집합으로, 데이터의 중복을 허용하지 않음.
|
HashSet, TreeSet
|
|
Map<K, V>
|
키와 값의 한 쌍으로 이루어지는 데이터의 집합으로, 순서가 없음.
이때 키는 중복을 허용하지 않지만, 값은 중복될 수 있음.
|
HashMap, TreeMap, Hashtable, Properties
|
1-2. 컬렉션 프레임웍별 특징

|
메소드
|
설명
|
|
boolean add(E e)
|
해당 컬렉션(collection)에 전달된 요소를 추가함. (선택적 기능)
|
|
void clear()
|
해당 컬렉션의 모든 요소를 제거함. (선택적 기능)
|
|
boolean contains(Object o)
|
해당 컬렉션이 전달된 객체를 포함하고 있는지를 확인함.
|
|
boolean equals(Object o)
|
해당 컬렉션과 전달된 객체가 같은지를 확인함.
|
|
boolean isEmpty()
|
해당 컬렉션이 비어있는지를 확인함.
|
|
Iterator<E> iterator()
|
해당 컬렉션의 반복자(iterator)를 반환함.
|
|
boolean remove(Object o)
|
해당 컬렉션에서 전달된 객체를 제거함. (선택적 기능)
|
|
int size()
|
해당 컬렉션의 요소의 총 개수를 반환함.
|
|
Object[] toArray()
|
해당 컬렉션의 모든 요소를 Object 타입의 배열로 반환함.
|
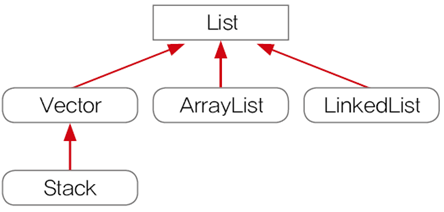
List 인터페이스
- 중복을 허용하면서 저장순서가 유지되는 컬렉션 구현

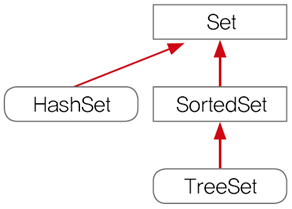
Set 인터페이스
- 중복을 허용하지 않고 저장순서가 유지되지않는 컬렉션 구현

Map 인터페이스
- 키와 값을 하나의 쌍으로 묶어서 저장하는 컬렉션 구현
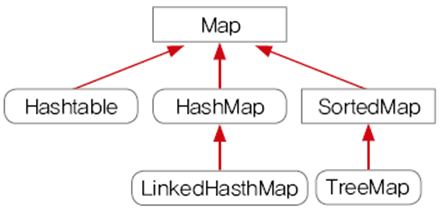
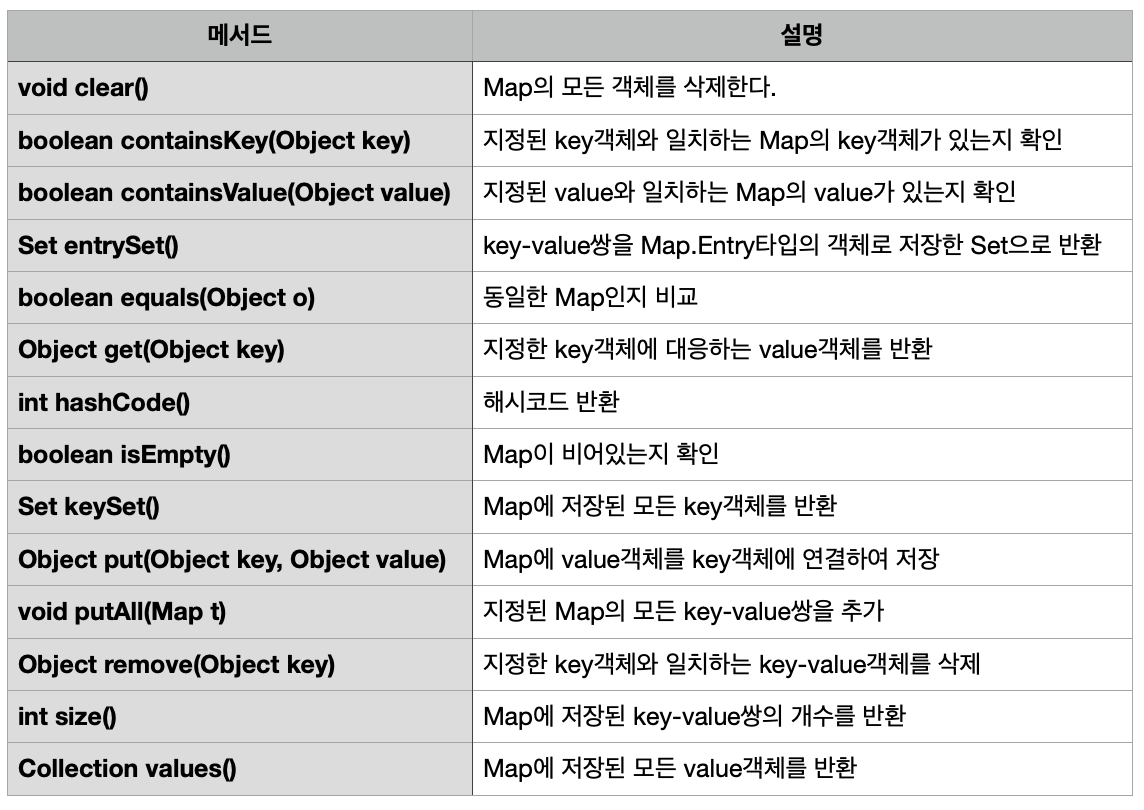
Map.Entry 인터페이스
- Map 인터페이스의 내부 인터페이스
|
메소드
|
설명
|
|
boolean equals(Object o)
|
동일한 Entry 인지 비교한다.
|
|
Object getKey()
|
Entry의 key 객체를 반환한다.
|
|
Object getValue()
|
Entry 의 value 객체를 반환한다.
|
|
int hashCode()
|
Entry 의 해시코드를 반환한다.
|
|
Object setValue(Object value)
|
Entry의 value 객체를 지정된 객체로 변경한다.
|
1-3. ArrayList
- List 인터페이스를 구현하기 때문에 데이터의 저장순서가 유지되고 중복을 허용
- Object 배열을 이용해 데이터를 순차적으로 저장
- 배열을 더이상 저장할 공간이 없는 경우, 보다 큰 배열을 생성해서 기존의 배열에 저장된 내용을 새로운 배열로 복사한 다음 저장한다.
- ArrayList나 Vector같이 배열을 이용한 자료구조는 데이터를 읽어오고 저장하는 데는 효율이 좋지만, 용량을 변경해야 할 때는 새로운 배열을 생성한 후 기존의 배열로부터 새로 생성된 배열로 데이터를 복사해야 하기 때문에 상당히 효율이 떨어진다는 단점을 가진다. 그래서 처음에 인스턴스를 생성할 때, 저장할 데이터의 개수를 잘 고려하여 충분한 용량의 인스턴스를 생성하는 것이 좋다.
- 생성자
|
|
|
|
|
|
|
|
- ArrayList의 메서드
|
Modifier and Type
|
Method
|
Description
|
|
void
|
Inserts the specified element at the specified position in this list.
|
|
|
boolean
|
Appends the specified element to the end of this list.
|
|
|
boolean
|
addAll(int index, Collection<? extends E> c)
|
Inserts all of the elements in the specified collection into this list, starting at the specified position.
|
|
boolean
|
addAll(Collection<? extends E> c)
|
Appends all of the elements in the specified collection to the end of this list, in the order that they are returned by the specified collection's Iterator.
|
|
void
|
clear()
|
Removes all of the elements from this list.
|
|
clone()
|
Returns a shallow copy of this ArrayList instance.
|
|
|
boolean
|
Returns true if this list contains the specified element.
|
|
|
void
|
ensureCapacity(int minCapacity)
|
Increases the capacity of this ArrayList instance, if necessary, to ensure that it can hold at least the number of elements specified by the minimum capacity argument.
|
|
void
|
Performs the given action for each element of the Iterable until all elements have been processed or the action throws an exception.
|
|
|
get(int index)
|
Returns the element at the specified position in this list.
|
|
|
int
|
Returns the index of the first occurrence of the specified element in this list, or -1 if this list does not contain the element.
|
|
|
boolean
|
isEmpty()
|
Returns true if this list contains no elements.
|
|
iterator()
|
Returns an iterator over the elements in this list in proper sequence.
|
|
|
int
|
lastIndexOf(Object o)
|
Returns the index of the last occurrence of the specified element in this list, or -1 if this list does not contain the element.
|
|
Returns a list iterator over the elements in this list (in proper sequence).
|
||
|
listIterator(int index)
|
Returns a list iterator over the elements in this list (in proper sequence), starting at the specified position in the list.
|
|
|
remove(int index)
|
Removes the element at the specified position in this list.
|
|
|
boolean
|
Removes the first occurrence of the specified element from this list, if it is present.
|
|
|
boolean
|
removeAll(Collection<?> c)
|
Removes from this list all of its elements that are contained in the specified collection.
|
|
boolean
|
Removes all of the elements of this collection that satisfy the given predicate.
|
|
|
protected void
|
removeRange(int fromIndex, int toIndex)
|
Removes from this list all of the elements whose index is between fromIndex, inclusive, and toIndex, exclusive.
|
|
boolean
|
retainAll(Collection<?> c)
|
Retains only the elements in this list that are contained in the specified collection.
|
|
Replaces the element at the specified position in this list with the specified element.
|
||
|
int
|
size()
|
Returns the number of elements in this list.
|
|
Creates a late-binding and fail-fast Spliterator over the elements in this list.
|
||
|
subList(int fromIndex, int toIndex)
|
Returns a view of the portion of this list between the specified fromIndex, inclusive, and toIndex, exclusive.
|
|
|
Object[]
|
toArray()
|
Returns an array containing all of the elements in this list in proper sequence (from first to last element).
|
|
<T> T[]
|
toArray(T[] a)
|
Returns an array containing all of the elements in this list in proper sequence (from first to last element); the runtime type of the returned array is that of the specified array.
|
|
void
|
Trims the capacity of this ArrayList instance to be the list's current size.
|
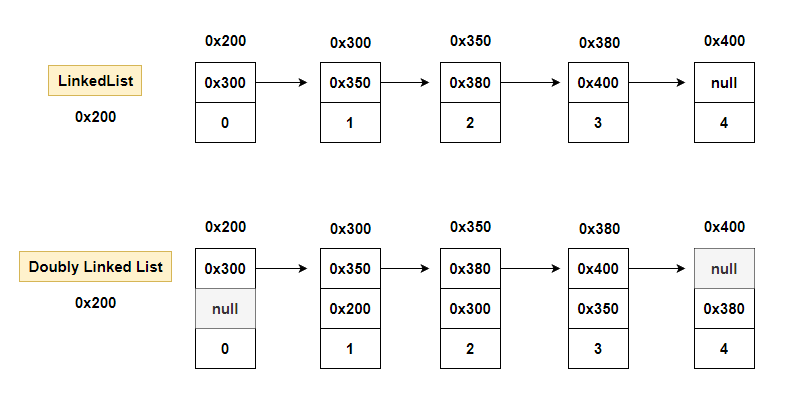
1-4. LinkedList
- 크기를 변경할 수 없고
- 비순차적인 데이터의 추가 또는 삭제에 시간이 많이 걸린다는
위와 같은 배열의 단점을 보완하기 위해 LInkedList 가 고안됨
배열은 모든 데이터가 연속적으로 존재하지만
링크드 리스트는 불연속적으로 존재하는 데이터를 서로 연결한 형태로 구성된다.
class Node {
Node next; // 다음 노드 주소를 저장하는 필드
int data; // 데이터를 저장하는 필드
};
출처: https://inpa.tistory.com/entry/JAVA-☕-LinkedList-구조-사용법-완벽-정복하기 [Inpa Dev 👨💻:티스토리]링크드 리스트 데이터 구조
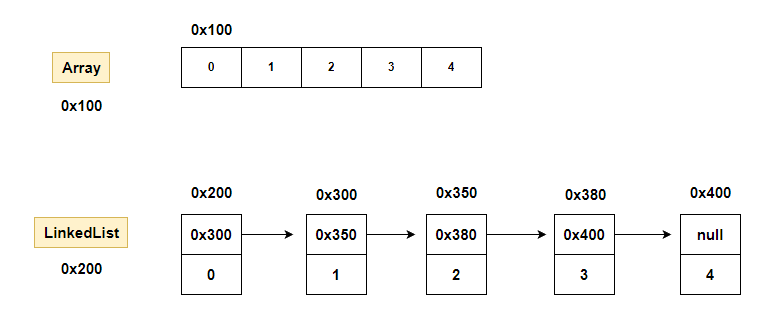
링크드 리스트의 각 요소(node)들은 자신과 연결된 다음 요소에 대한 참조(주소값)와 데이터로 구성
import java.util.List;
import java.util.LinkedList;
List<타입> list1 = new LinkedList<>();
List<타입> list2 = new LinkedList<>(list1); // 주어진 컬렉션을 포함하는 LinkedList 객체 생성
링크드리스트에서 데이터 삭제
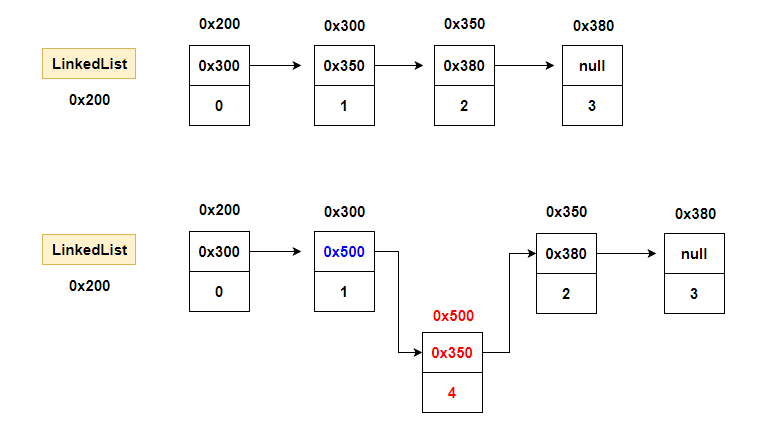
삭제하고자 하는 요소의 이전 요소가 삭제하고자 하는 요소의 다음 요소를 참조하도록 변경.
단 하나의 참조만 변경하면 삭제가 이루어짐.
배열처럼 데이터를 이동하기 위해 복사하는 과정이 없어 처리속도가 빠름
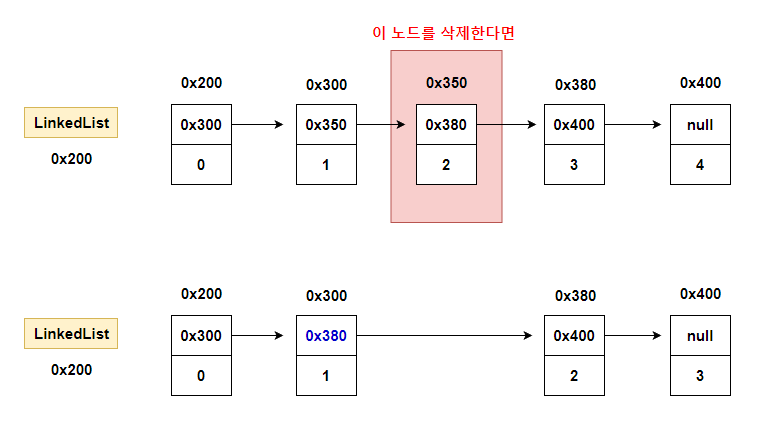
링크드리스트에서 데이터 추가
데이터를 추가할 때는, 새로운 요소를 생성한 다음 추가하고자 하는 이전 요소의 참조를 새로운 요소에 대한 참조로 변경한다.
그리고, 새로운 요소가 그 다음 요소를 참조하도록 변경하기만 하면 되므러 처리 속도가 빠르다.
단방향 링크드 리스트 / 양방향 링크드 리스트
양방향
class Node {
Node next; // 다음 노드 주소를 저장하는 필드
int previous; // 이전 노드 주소를 저장하는 필드
Object obj; // 데이터를 저장
};
링크드 리스트의 메서드
|
메서드
|
반환 타입
|
설 명
|
|
add(Object o)
|
boolean
|
지정된 객체(o)를 LikedList 끝에 추가
|
|
add(int i, Object element)
|
void
|
지정된 위치(i)에 객체(element)를 추가
|
|
addAll(Collection c)
|
boolean
|
주어진 컬렉션에 포함된 모든 요소를 LikedList 의 끝에 추가.
|
|
addAll(int i, Collection c)
|
boolean
|
지정된 위치(i)에 주어진 컬렉션에 포함된 모든 요소를 추가
|
|
clear()
|
void
|
LikedList의 모든 요소 삭제
|
|
contains(Object o)
|
boolean
|
지정된 객체가 LikedList에 포함되어있는지 확인
|
|
containsAll(Collection c)
|
boolean
|
지정된 컬렉션의 모든 요소가 포함되어있는지 확인
|
|
get(int i)
|
Object
|
지정된 위치(i)의 객체를 반환
|
|
indexOf(Object o)
|
int
|
지정된 객체가 저장된 위치(앞에서 부터 몇번째) 반환
|
|
isEmpty()
|
boolean
|
LikedList가 비었는지 확인
|
|
iterator()
|
lterator
|
lterator를 반환
|
|
lastIndexOf(Object o)
|
int
|
지정된 객체의 위치(i)를 반환( 끝부터 역순 )
|
|
listlterator()
|
Listlterator
|
Listlterator를 반환
|
|
listlterator(int i)
|
Listlterator
|
지정된 위치에서부터 시작하는 Listlterator를 반환
|
|
remove(int i)
|
Object
|
지정된 위치(i)의 객체를 LikedList에서 제거
|
|
remove(Object o)
|
boolean
|
지정된 객체를 LikedList에서 제거
|
|
removeAll(Collection c)
|
boolean
|
지정된 컬렉션의 요소와 일치하는 요소를 모두 삭제
|
|
retainAll(Collection c)
|
boolean
|
지정된 컬렉션의 모든 요소가 포함되어 있는지 확인
|
|
set(int i, Object element)
|
Object
|
지정된 위치(i)의 객체를 주어진 객체로 바꿈
|
|
size()
|
int
|
LikedList에 저장된 객체의 수를 반환
|
|
subList(int start, int end)
|
List
|
LikedList의 일부를 List로 반환
|
|
toArray()
|
Object[]
|
LikedList의 저장된 객체를 배열로 변환
|
|
toArray(Object [])
|
Object[]
|
LikedList에 저장된 객체를 주어진 배열에 저장하여 반환
|
|
element()
|
Object
|
LikedList의 첫 번째 요소 반환
|
|
offer(Object o)
|
boolean
|
지정된 객체(o)를 LikedList의 끝에 추가
|
|
peek()
|
Object
|
LikedList의 첫 번재 요소를 반환
|
|
poll()
|
Object
|
LikedList의 첫 번째 요소를 반환하고 LikedList에서 제거된다.
|
|
remove()
|
Object
|
LikedList의 첫 번째 요소 제거
|
|
addfirst(Object o)
|
void
|
LikedList의 맨 앞에 객체(o)를 추가
|
|
addLast(Object o)
|
void
|
LikedList의 맨 끝에 객체(o)를 추가
|
|
descendinglterator()
|
lterator
|
역순으로 조회하기 위한 Descendinglterator를 반환
|
|
getFirst()
|
Object
|
LikedList의 첫 번째 요소를 반환
|
|
getLast()
|
Object
|
LikedList의 마지막 요소를 반환
|
|
offerFirst(Object o)
|
boolean
|
LikedList의 맨 앞에 객체(o)를 추가.
|
|
offerLast(Object o)
|
boolean
|
LikedList의 맨 끝에 객체(o)를 추가
|
|
peekFirst()
|
Object
|
LikedList의 첫 번재 요소를 반환
|
|
peekLast()
|
Object
|
LikedList의 마지막 요소를 반환
|
|
pollFirst()
|
Object
|
LikedList의 첫 번째 요소를 반환하면서 제거
|
|
pollLast()
|
Object
|
LikedList의 마지막 요소를 반환하면서 제거
|
|
pop()
|
Object
|
removeFirst()와 같다.
|
|
push(Object o)
|
void
|
addFirst()와 같다.
|
|
removeFirst()
|
Object
|
LikedList의 첫 번째 요소를 제거
|
|
removeLast()
|
Object
|
LikedList의 마지막 요소를 제거
|
|
removeFirstOccurrence(Object o)
|
boolean
|
LikedList에서 첫 번째로 일치하는 객체를 제거
|
|
removeLastOccurrence(Object o)
|
boolean
|
LikedList에서 마지막으로 일치하는 객체를 제거
|
출처: https://hstory0208.tistory.com/entry/Java자바-LinkedList-클래스-사용법 [< Hyun / Log >:티스토리]
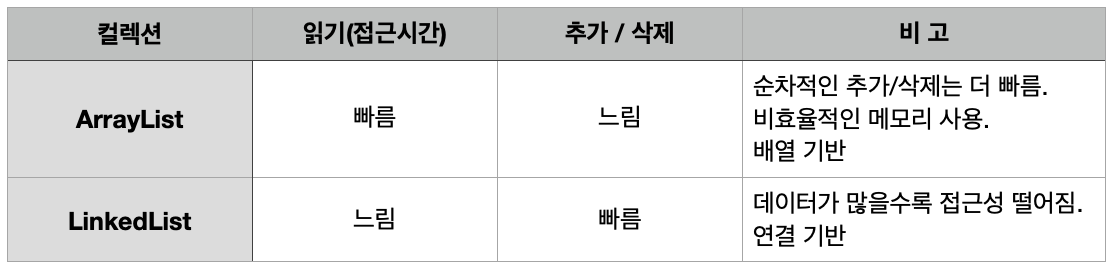
LinkedList와 ArrayList의 차이
요약

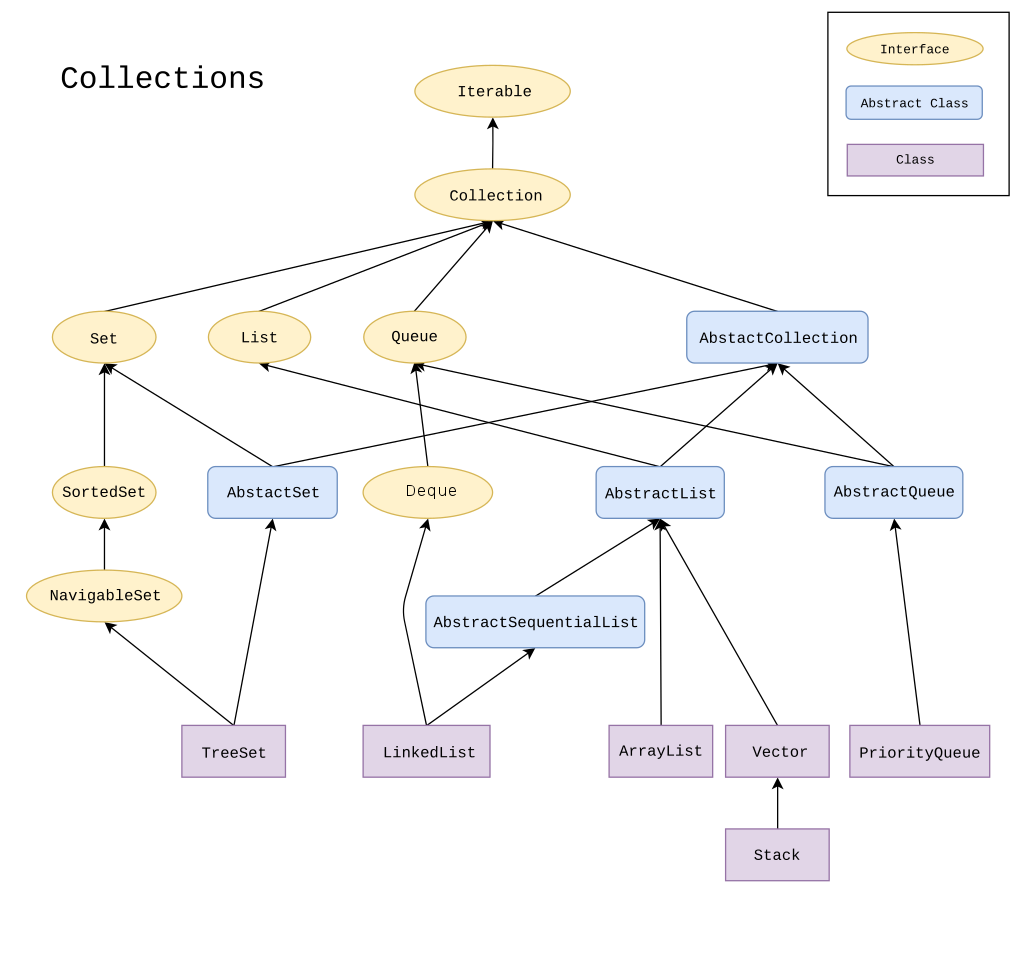
1-5. Stack과 Queue
LIFO구조와 FIFO구조
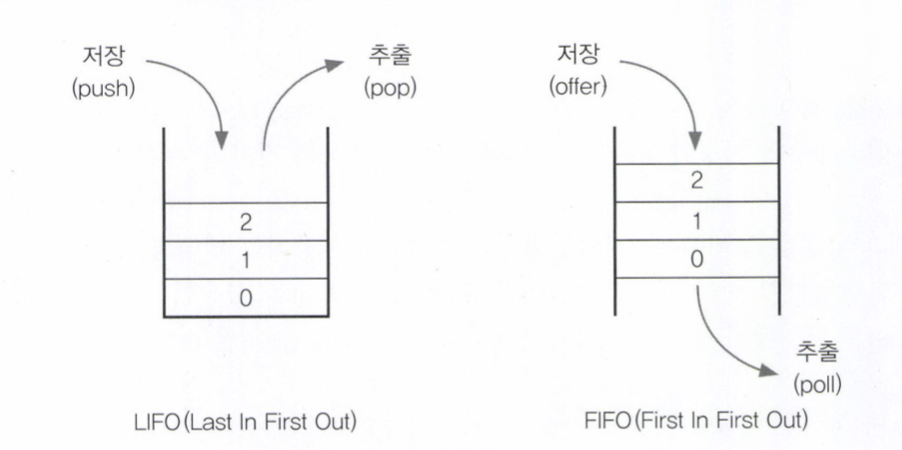
Stack
스택은 순차적으로 데이터를 추가하고 삭제하기 때문에 ArrayList와 같은 배열기반의 컬렉션 클래스가 적합
활용 예) 수식계산, 수식괄호검사, 워드프로세서의 undo/redo,
웹브라우저의 뒤로/앞으로, undo(실행취소: ctrl+z), redo(되돌리기:ctril+y), 역순문자열만들기,
후위표기법계산수식의괄호검사(연산자 우선순위 표현을 위한 괄호 검사),
웹 브라우저 방문기록(가장 나중에 열린 페이지부터 다시 보여준다.)
1. 먼저 들어간 자료가 나중에 나옴 LIFO(Last In First Out) 구조
2. 시스템 해킹에서 버퍼오버플로우 취약점을 이용한 공격을 할 때 스택 메모리의 영역에서 함
3. 인터럽트처리, 수식의 계산, 서브루틴의 복귀 번지 저장 등에 쓰임
4. 그래프의 깊이 우선 탐색(DFS)에서 사용
5. 재귀적(Recursion) 함수를 호출 할 때 사용
링크드 리스트의 메서드
메서드
반환 타입
설 명
add(Object o)
boolean
지정된 객체(o)를 LikedList 끝에 추가
add(int i, Object element)
void
지정된 위치(i)에 객체(element)를 추가
addAll(Collection c)
boolean
주어진 컬렉션에 포함된 모든 요소를 LikedList 의 끝에 추가.
addAll(int i, Collection c)
boolean
지정된 위치(i)에 주어진 컬렉션에 포함된 모든 요소를 추가
clear()
void
LikedList의 모든 요소 삭제
contains(Object o)
boolean
지정된 객체가 LikedList에 포함되어있는지 확인
containsAll(Collection c)
boolean
지정된 컬렉션의 모든 요소가 포함되어있는지 확인
get(int i)
Object
지정된 위치(i)의 객체를 반환
indexOf(Object o)
int
지정된 객체가 저장된 위치(앞에서 부터 몇번째) 반환
isEmpty()
boolean
LikedList가 비었는지 확인
iterator()
lterator
lterator를 반환
lastIndexOf(Object o)
int
지정된 객체의 위치(i)를 반환( 끝부터 역순 )
listlterator()
Listlterator
Listlterator를 반환
listlterator(int i)
Listlterator
지정된 위치에서부터 시작하는 Listlterator를 반환
remove(int i)
Object
지정된 위치(i)의 객체를 LikedList에서 제거
remove(Object o)
boolean
지정된 객체를 LikedList에서 제거
removeAll(Collection c)
boolean
지정된 컬렉션의 요소와 일치하는 요소를 모두 삭제
retainAll(Collection c)
boolean
지정된 컬렉션의 모든 요소가 포함되어 있는지 확인
set(int i, Object element)
Object
지정된 위치(i)의 객체를 주어진 객체로 바꿈
size()
int
LikedList에 저장된 객체의 수를 반환
subList(int start, int end)
List
LikedList의 일부를 List로 반환
toArray()
Object[]
LikedList의 저장된 객체를 배열로 변환
toArray(Object [])
Object[]
LikedList에 저장된 객체를 주어진 배열에 저장하여 반환
element()
Object
LikedList의 첫 번째 요소 반환
offer(Object o)
boolean
지정된 객체(o)를 LikedList의 끝에 추가
peek()
Object
LikedList의 첫 번재 요소를 반환
poll()
Object
LikedList의 첫 번째 요소를 반환하고 LikedList에서 제거된다.
remove()
Object
LikedList의 첫 번째 요소 제거
addfirst(Object o)
void
LikedList의 맨 앞에 객체(o)를 추가
addLast(Object o)
void
LikedList의 맨 끝에 객체(o)를 추가
descendinglterator()
lterator
역순으로 조회하기 위한 Descendinglterator를 반환
getFirst()
Object
LikedList의 첫 번째 요소를 반환
getLast()
Object
LikedList의 마지막 요소를 반환
offerFirst(Object o)
boolean
LikedList의 맨 앞에 객체(o)를 추가.
offerLast(Object o)
boolean
LikedList의 맨 끝에 객체(o)를 추가
peekFirst()
Object
LikedList의 첫 번재 요소를 반환
peekLast()
Object
LikedList의 마지막 요소를 반환
pollFirst()
Object
LikedList의 첫 번째 요소를 반환하면서 제거
pollLast()
Object
LikedList의 마지막 요소를 반환하면서 제거
pop()
Object
removeFirst()와 같다.
push(Object o)
void
addFirst()와 같다.
removeFirst()
Object
LikedList의 첫 번째 요소를 제거
removeLast()
Object
LikedList의 마지막 요소를 제거
removeFirstOccurrence(Object o)
boolean
LikedList에서 첫 번째로 일치하는 객체를 제거
removeLastOccurrence(Object o)
boolean
LikedList에서 마지막으로 일치하는 객체를 제거
출처: https://hstory0208.tistory.com/entry/Java자바-LinkedList-클래스-사용법 [< Hyun / Log >:티스토리]
LinkedList와 ArrayList의 차이
요약
1-5. Stack과 Queue
LIFO구조와 FIFO구조
Stack
스택은 순차적으로 데이터를 추가하고 삭제하기 때문에 ArrayList와 같은 배열기반의 컬렉션 클래스가 적합
활용 예) 수식계산, 수식괄호검사, 워드프로세서의 undo/redo, 웹브라우저의 뒤로/앞으로, undo(실행취소: ctrl+z), redo(되돌리기:ctril+y), 역순문자열만들기, 후위표기법계산수식의괄호검사(연산자 우선순위 표현을 위한 괄호 검사), 웹 브라우저 방문기록(가장 나중에 열린 페이지부터 다시 보여준다.)
1. 먼저 들어간 자료가 나중에 나옴 LIFO(Last In First Out) 구조
2. 시스템 해킹에서 버퍼오버플로우 취약점을 이용한 공격을 할 때 스택 메모리의 영역에서 함
3. 인터럽트처리, 수식의 계산, 서브루틴의 복귀 번지 저장 등에 쓰임
4. 그래프의 깊이 우선 탐색(DFS)에서 사용
5. 재귀적(Recursion) 함수를 호출 할 때 사용
import java.util.Stack;
class StackEx {
public static void main(String[] args) {
// Integer형 스택 선언
Stack<Integer> stackInt = new Stack<>();
// String형 스택 선언
Stack<String> stackStr = new Stack<>();
// Boolean형 스택 선언
Stack<Boolean> stackBool = new Stack<>();
// 값 추가 push()
stackInt.push(1);
stackInt.push(2);
stackInt.push(3);
// 1, 2, 3 순으로 값 추가
// 값 제거
stackInt.pop();
stackInt.pop();
stackInt.pop();
// 3, 2, 1 순으로 값 제거
// 값 추가 add()
stackInt.add(1);
stackInt.add(2);
stackInt.add(3);
// 1, 2, 3 순으로 값 추가
// 값 모두 제거
stackInt.clear();
}
}
}
출처: https://ittrue.tistory.com/200 [IT is True:티스토리]
Stack의 메서드

Queue
큐는 데이터의 추가/삭제가 쉬운 LInkedList로 구현하는 것이 더 적합
활용 예) 최근사용문서, 인쇄작업 대기목록, 버퍼(buffer), 우선순위가 같은 작업 예약, 은행 업무,
콜센터 고객 대기시간, 프로세스 관리, 너비 우선 탐색(BFS, Breadth-First Search) 구현, 캐시(Cache) 구현
1. 먼저 들어간 자료가 먼저 나오는 구조 FIFO(First In FIrst Out) 구조
2. 큐는 한 쪽 끝은 프런트(front)로 정하여 삭제 연산만 수행함
3. 다른 한 쪽 끝은 리어(rear)로 정하여 삽입 연산만 수행함
4. 그래프의 넓이 우선 탐색(BFS)에서 사용
5. 컴퓨터 버퍼에서 주로 사용, 마구 입력이 되었으나 처리를 하지 못할 때, 버퍼(큐)를 만들어 대기 시킴
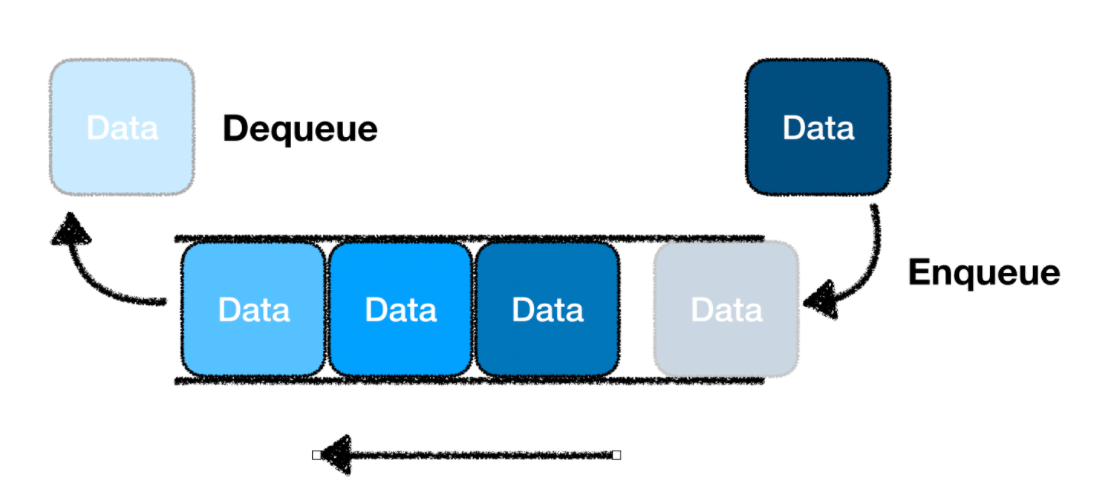
Enqueue : 큐 맨 뒤에 데이터 추가
Dequeue : 큐 맨 앞쪽의 데이터 삭제
Queue 메서드
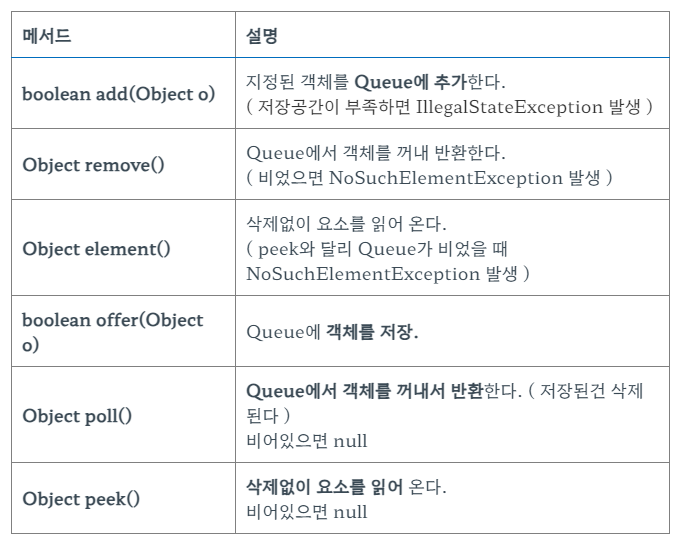
Stack과 Queue 비교
import java.util.Stack;
import java.util.LinkedList;
import java.util.Queue;
class StackQueueEx {
public static void main(String[] args) {
Stack st = new Stack();
Queue q = new LinkedList(); // Queue인터페이스의 구현체인 LinkedList를 사용
// Stack에 값 넣기
st.push("0");
st.push("1");
st.push("2");
// Queue에 값 넣기
q.offer("0");
q.offer("1");
q.offer("2");
System.out.println("= Stack =");
while(!st.empty()) {
System.out.println(st.pop());
}
System.out.println("= Queue =");
while(!q.isEmpty()) {
System.out.println(q.poll());
}
}
}
PriorityQueue(우선순위큐)
Queue 인터페이스의 구현체 중의 하나로, 저장한 순서에 관계없이 우선순위가 높은 것부터 꺼낸다.
PriorityQueue는 null은 저장할 수 없으며, null을 저장할 시 NullPointerException이 발생한다.
PriorityQueue는 저장공간을 배열을 사용하며, 각 요소를 "힙(heap)"이라는 자료구조의 형태로 저장한다. 힙(heap)은 가장 큰 값이나 가장 작은 값을 빠르게 찾을 수 있다는 특징을 가진다.
출처: https://hstory0208.tistory.com/entry/Java자바-스택Stack과-큐Queue [< Hyun / Log >:티스토리]
import java.util.PriorityQueue;
import java.util.Queue;
class PriorityQueueEx {
public static void main(String[] args) {
Queue pq = new PriorityQueue();
pq.offer(3);
pq.offer(1);
pq.offer(5);
pq.offer(2);
pq.offer(4);
System.out.println(pq); // pq의 내부 배열을 출력
Object obj = null;
// PriorityQueue에 저장된 요소를 하나씩 꺼낸다.
while((obj = pq.poll())!=null)
System.out.println(obj);
}
}
DeQueue(Double-Ended Queue)
Deque는 양쪽 끝에 추가,삭제가 가능하다. ( 스택과 큐를 하나로 합쳐놓은 것과 같다. )
Deque의 조상은 Queue이고, 구현체로는 ArrayDeque, LinkedList 등이 있다.
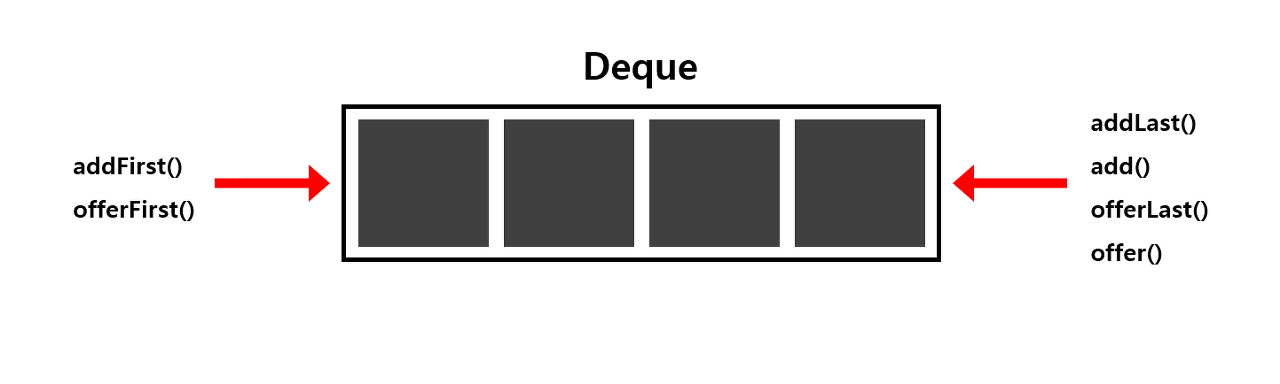
import java.util.Deque;
import java.util.LinkedList;
import java.util.Queue;
Deque deque = new LinkedList();
Deque deque = new ArrayDeque();
덱의 메서드에 대응하는 큐와 스택의 메서드
|
Deque
|
Queue
|
Stack
|
|
offerLast()
|
offer()
|
push()
|
|
pollLast()
|
-
|
pop()
|
|
peekFirst()
|
peek()
|
-
|
|
peekLast()
|
-
|
peek()
|
1-6. Iterator, ListIterator, Enumeration
Iterator
자바의 컬렉션에 저장되어 있는 요소들을 읽어오는 방법의 인터페이스
public void linkedListTest() {
LinkedList<Integer> list = new LinkedList<Integer>();
for(int i = 0;i <= 100; i++) {
list.add(i);
}
for(int i = 0; i<= 100; i++) {
list.get(i);
}
}
Iterator의 메서드
|
메서드
|
설명
|
|
boolean hasNext()
|
해당 이터레이션(iteration)이 다음 요소를 가지고 있으면 true를 반환하고, 더 이상 다음 요소를 가지고 있지 않으면 false를 반환함.
|
|
E next()
|
이터레이션(iteration)의 다음 요소를 반환함.
|
|
default void remove()
|
해당 반복자로 반환되는 마지막 요소를 현재 컬렉션에서 제거함. (선택적 기능)
|
출처: https://junghn.tistory.com/entry/JAVA-Iterator이란-사용법-예제-장점과-단점 [코딩 시그널:티스토리]
장점과 단점
Iterator 개체를 사용하면 size 메서드를 얻어와서 반복 처리하는 것보다 속도에서 불리합니다. 이는 Iterator 개체를 사용하는 부분이 있기 때문에 불가피한 사항입니다. 하지만 컬렉션 종류에 관계없이 일관성 있게 프로그래밍할 수 있다는 장점을 갖고 있습니다. 소스 코드에 어떠한 컬렉션을 사용할지 정해지지 않았지만 컬렉션 내에 보관한 모든 내용을 출력하는 등의 작업을 먼저 하길 원한다면 Iterator를 사용하는 것은 좋은 선택입니다.
ListIterator : Iterator에 양방향 조회기능추가 (List를 구현한 경우만 사용가능)
LinkedList<Integer> lnkList = new LinkedList<Integer>();
lnkList.add(4);
lnkList.add(2);
lnkList.add(3);
lnkList.add(1);
Iterator<Integer> iter = lnkList.iterator();
while (iter.hasNext()) {
System.out.print(iter.next() + " ");
}
ListIterator의 메서드
|
메소드
|
설명
|
|
boolean hasNext()
|
해당 이터레이션(iteration)이 다음 요소를 가지고 있으면 true를 반환하고, 더 이상 다음 요소를 가지고 있지 않으면 false를 반환함.
|
|
E next()
|
이터레이션(iteration)의 다음 요소를 반환함.
|
|
default void remove()
|
해당 반복자로 반환되는 마지막 요소를 현재 컬렉션에서 제거함. (선택적 기능)
|
Enumeration : Iterator의 구버전
public class EnumerationTest{
public static void main(String[] args) {
Vector<String> v1 = new Vector<String>(2);
v1.addElement("삼성");
v1.addElement("LG");
v1.addElement("SK");
v1.addElement("구글");
System.out.println("Vector 요소들은 다음과 같다.");
for(int i=0; i<v1.size(); i++){
System.out.println("v1의 "+i+"번째 요소 : "+v1.elementAt(i));
}
Enumeration<String> e = v1.elements();
System.out.println();
System.out.println("Vector v1으로부터 생성한 Enumeration의 요소들은 다음과 같다.");
while(e.hasMoreElements()){
System.out.println("e의 요소 : "+e.nextElement());
}
}
}
1-7. Arrays
배열의 복사 - copyOf(), copyOfRange()
배열 채우기 - fill(), setAll()
배열의 정렬과 검색 - sort(), binarySearch()
배열의 비교와 출력 - equals(), toString()
배열을 List로 변환 - asList(Object ... a)
1-8. Comparator, Comparable
Comparator - 기본 정렬기준을 구현하는데 사용
Comparable - 기본 정렬기준 외에 다른 기준으로 정렬하고자할 때 사용
1-9. HashSet
set인터페이스를 구현한 가장 대표적인 컬렉션으로, set인터페이스의 특징대로 HashSet은 중복된 요소를 저장하지 않는다.
기존에 있는 요소 혹은 중복된 요소를 저장하려고 시도 시 (add(), addAll()) 이 메서드들이 false를 반환함으로써 추가에 실패했음을 알린다.
ArrayList와 같이 List 인터페이스를 구현한 컬렉션과 달리 HashSet은 저장순서를 유지하지 않으므로 저장순서를 유지하고자 한다면 LinkedHashSet을 사용해야 한다.
⑴ 실행 중인 애플리케이션 내의 동일한 객체에 대해서 여러 번 hashCode()를 호출해도 동일한 int의 값을 반환해야 한다. 하지만, 실행시마다 동일한 int값을 반환할 필요는 없다.
⑵ equals메서드를 이용한 비교에 의해서 true를 얻은 두 객체에 대해 각각 hashCode()를 호출해서 얻은 결과는 반드시 같아야 한다.
⑶ equals메서드를 호출했을 때 false를 반환하는 두 객체는 hashcode() 호출에 대해 같은 int값을 반환하는 경우가 있어도 괜찮지만, 해싱을 사용하는 컬렉션의 성능을 향상시키기 위해서는 다른 int값을 반환하는 것이 좋다.
1-10. TreeSet
이진 검색 트리 구조의 하나로 데이터를 저장하는 컬렉션 클래스.
이진 검색 트리는 정렬, 검색, 범위검색에 높은 성능을 보이는 자료구조이며, treeset은 이진 검색 트리의 성능을 향상시킨 레드-블랙 트리로 구현되어 있다.
* 레드-블랙 트리 : 부모노드보다 작은 값을 가지는 노드는 왼쪽 자식으로, 큰 값을 가지는 노드는 오른쪽 자식으로 배치하여 데이터의 추가나 삭제 시 트리가 한쪽으로 치우쳐지지 않도록 균형을 맞춤
그리고 set 인터페이스를 구현했으므로 중복된 데이터의 저장을 허용하지 않으며 정렬된 위치에 저장하므로 저장순서를 유지하지도 않는다.
이진 트리는 링크드리스트처럼 여러 개의 노드가 서로 연결된 구조로, 각 노드에 최대 2개의 노드를 연결할 수 있으며, 루트라고 불리는 하나의 노드에서부터 시작해 계속 확장해나갈 수 있다.


class TreeNode {
private int data; // 왼쪽 자식노드
private TreeNode left; // 객체를 저장하기 위한 참조변수
private TreeNode right; // 오른쪽 자식노드
}
이진 트리의 특징
- 모든 노드는 최대 두 개의 자식노드를 가질 수 있다.
- 왼쪽 자식노드의 값은 부모노드의 값보다 작고 오른쪽 자식노드의 값은 부모노드의 값보다 커야 한다. (작은 값은 왼쪽, 큰 값은 오른쪽에 저장한다.)
- 노드의 추가 삭제에 시간이 걸린다. (순차적으로 저장하지 않으므로)
- 검색(범위검색)과 정렬에 유리하다.
- 중복된 값을 저장하지 못한다.
- 첫 번쨰로 저장되는 값은 루트가 되고, 두 번째 값은 트리의 루트부터 시작해서 값의 크기를 비교하며 트리를 따라 내려간다.
TreeSet 메서드
|
메서드
|
반환 타입
|
설 명
|
|
add(Object o)
|
boolean
|
주어진 객체(o)를 추가
|
|
addAll(Collection c)
|
boolean
|
지정된 Collection(c)의 객체들을 추가
|
|
ceiling(Object o)
|
Object
|
지정된 객체와 같은 객체를 반환.
없다면 큰 값을 가진 객체 중 제일 가까운 값의 객체를 반환.
그래도 없으면 null
|
|
clear()
|
void
|
지정된 모든 객체 삭제
|
|
clone()
|
Object
|
TreeSet을 복제
|
|
comparator()
|
Comparator
|
TreeSet의 정렬기준을 반환
|
|
contains(Object o)
|
boolean
|
지정된 객체(o)가 포함되어 있는지 확인
|
|
containsAll(Collection c)
|
boolean
|
주어진 컬렉션의 객체들이 모두 포함되어 있는지 확인
|
|
descendingSet()
|
NavigableSet
|
TreeSet에 저장된 요소들을 역순으로 정렬해서 반환
|
|
first()
|
Object
|
정렬된 순서에서 첫 번째 객체 반환
|
|
last()
|
Object
|
정렬된 순서에서 마지막 객체 반환
|
|
floor(Object o)
|
Object
|
지정된 객체와 같은 객체를 반환.
없으면 작은 값을 가진 객체 중 제일 가까운 값의 객체 반환.
그래도 없으면 null
|
|
headSet(Object toElement)
|
SortedSet
|
지정된 객체보다 작은 값의 객체들을 반환
|
|
headSet(Object toElement, boolean inclusive)
|
NavigableSet
|
지정된 객체보다 작은 값의 객체들을 반환.
inclusive가 true면 같은 값의 객체도 포함.
|
|
higher(Object o)
|
Object
|
지정된 객체보다 큰 값을 가진 객체 중 제일 가까운 값의 객체를 반환.
없으면 null.
|
|
lower(Object o)
|
Object
|
지정된 객체보다 작은 값을 가진 객체 중 제일 가까운 객체를 반환.
없으면 null
|
|
isEmpty()
|
boolean
|
TreeSet이 비었는지 확인
|
|
iterator()
|
Iterator
|
TreeSet의 Iterator를 반환
|
|
pollFirst()
|
Object
|
TreeSet의 첫 번째 요소 (제일 작은 값의 객체)를 반환
|
|
pollLast()
|
Object
|
TreeSet의 마지막 번째 요소 ( 제일 큰 값)을 반환
|
|
remove(Object o)
|
boolean
|
지정된 객체를 삭제
|
|
retainAll(Collection c)
|
boolean
|
주어진 컬렉션과 공통된 요소만을 남기고 삭제 ( 교집합 )
|
|
size()
|
int
|
TreeSet에 저장된 객체 수 반환
|
|
spliterator()
|
Spliterator
|
TreeSet의 spliterator를 반환
|
|
subSet(Object fromElement, Object toElement)
|
SortedSet
|
범위 검색 ( from와 to 사이)의 결과를 반환.
끝 범위 to는 포함 X
|
|
subSet(E fromElement, boolean fromInclusive,
E toElement, boolean toInclusive)
|
NavigableSet<E>
|
범위 검색 ( strat와 end 사이)의 결과를 반환.
( fromInclusiver가 true면 시작값 포함,
toInclusive가 true면 끝 값 포함. )
|
|
tailSet(Object fromElement)
|
SortedSet
|
지정된 객체보다 큰 값의 객체들을 반환
|
|
toArray()
|
Object[]
|
지정된 객체를 객체배열로 반환
|
|
toArray(Object[] a)
|
Object[]
|
저장된 객체를 주어진 객체배열에 저장하여 반환
|
출처: https://hstory0208.tistory.com/entry/Java자바-TreeSet-사용법 [< Hyun / Log >:티스토리]
1-11. HashMap과 Hashtable
HashMap은 Map을 구현했으므로 키와 값을 묶어 하나의 데이터(entry)로 저장한다는 특징을 갖는다. 그리고 해싱을 사용하기 때문에 많은 양의 데이터를 검ㅈ색하는데 있어서 뛰어난 성능을 보인다.
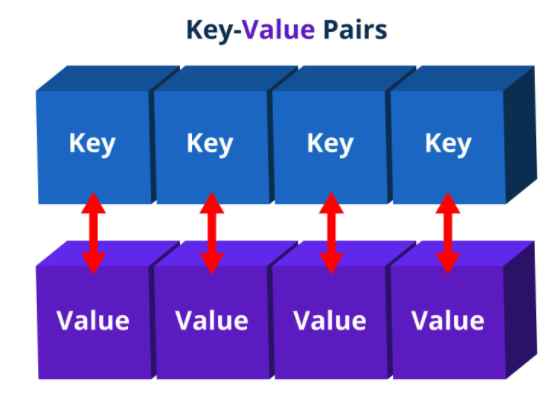
키(key) : 컬렉션 내의 키 중에서 유일해야 한다.
값(value) : 키와 달리 데이터의 중복을 허용한다.
HashMap 메서드
|
메서드
|
반환 타입
|
설 명
|
|
clear()
|
void
|
HashMap에 저장된 모든 객체를제거
|
|
clone()
|
Object
|
현재 HashMap을 복제해서 반환
|
|
containsKey(Object key)
|
boolean
|
HashMap에 지정된 키(key)가 포함되어있는지 확인
|
|
containsValue(Object value)
|
boolean
|
HashMap에 지정된 값(value)가 포함되어 있는지 확인
|
|
entrySet()
|
Set
|
HashMap에 저장된 키와 값을 엔트리(키와 값의 결합)의 형태로 Set에 저장해서 반환
|
|
get(Object key)
|
Object
|
지정된 키(key)의 값(value)를 반환.
못찾으면 null
|
|
getOrDefault(Object key, Object defaultValue)
|
Object
|
지정된 키(key)의 값(객체)를 반환하는데,
키를 못찾으면, 기본 값(defaultValue)로 지정된 객체를 반환
|
|
isEmpty
|
boolean
|
HashMap이 비어있는지 확인
|
|
keySet()
|
Set
|
HashMap에 저장된 모든 키가 저장된 Set을 반환
|
|
put(Object key, Object value)
|
Object
|
지정된 키와 값을 HashMap에 저장
|
|
putAll(Map m)
|
void
|
Map에 저장된 모든 요소를 HashMap에 저장
|
|
remove(Object key)
|
Object
|
HashMap에서 지정된 키로 저장된 값(value)를 제거
|
|
replace(Object key, Object value)
|
Object
|
지정된 키의 값을 지정된 객체(value)로 대체
|
|
replace(Object key, Object oldValue, Object newValue)
|
boolean
|
지정된 키와 객체(oldValue)가 모두 일치하는 경우에만 새로운 객체(newValue)로 대체
|
|
size()
|
int
|
HashMap에 저장된 요소의 개수를 반환
|
|
values()
|
Collection
|
HashMap에 저장된 모든 값을 컬렉션의 형태로 반환.
|
해싱과 해시함수
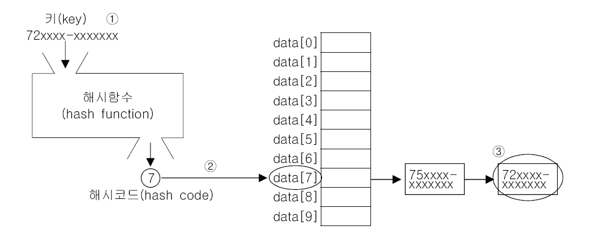
- 검색하고자 하는 값을 가진 Key로 해시함수를 호출한다.
- 해시함수의 계산결과(해시코드)로 해당 값이 저장되어 있는 요소에 접근한다.
- 요소안에 링크드리스트들을 조회하여 값을 찾는다.
해시 테이블
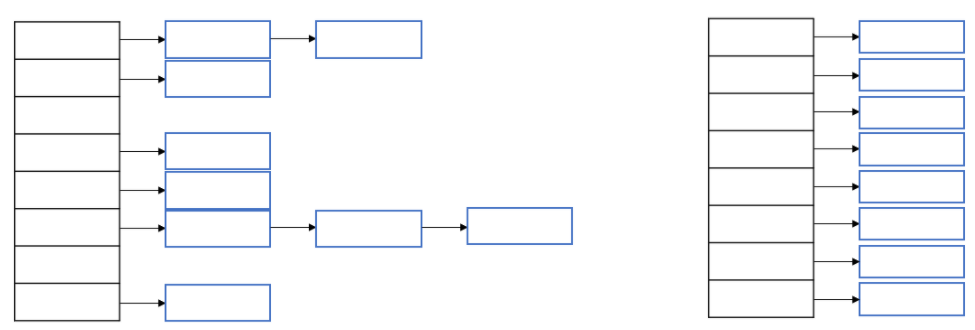
(왼) 해시코드의 성능이 좋지 않은경우, (오) 해시코드의 성능이 좋은 경우
배열의 인덱스가 n인 요소의 주소 = 배열의 시작주소 + type의 size * n
1-12. TreeMap
이진검색트리의 형태로 키와 값의 쌍으로 이루어진 데이터를 저장한다.
대부분의 경우 HashMap이 TreeMap보다 더 뛰어나므로 HashMap을 사용하는 것이 좋다.

class Node {
Object element; // 객체의 주소값을 저장하는 참조변수
Node left; // 왼쪽 자식 노드의 주소값을 저장하는 참조변수
Node right; // 오른쪽 자식 노드의 주소값을 저장하는 참조변수
}
출처: https://ittrue.tistory.com/154 [IT is True:티스토리]
TreeMap 예제
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class TreeMapEx {
public static void main(String[] args) {
// TreeMap 생성
TreeMap<Integer, String> treeMap = new TreeMap<>();
// TreeMap Entry 객체 저장
treeMap.put(1, "부산");
treeMap.put(2, "인천");
treeMap.put(3, "대구");
treeMap.put(4, "대전");
treeMap.put(5, "광주");
treeMap.put(6, "울산");
// 저장된 총 Entry 수 얻기
int size = treeMap.size();
System.out.println(size);
// 객체 찾기
Object object = treeMap.get(1);
System.out.println(object);
// key를 요소로 가지는 Set 생성
Set<Integer> keySet = treeMap.keySet();
System.out.println(keySet);
// value 값 읽기
Iterator<Integer> keyIterator = keySet.iterator();
while (keyIterator.hasNext()) {
Integer key = keyIterator.next();
String value = treeMap.get(key);
System.out.println("키: " + key + " 값: " + value);
}
// 객체 삭제 후 크기 출력
treeMap.remove(1);
System.out.println(treeMap.size());
// entrySet()을 활용한 value 값 읽기
for (Map.Entry<Integer, String> entry : treeMap.entrySet()) {
System.out.println("키: " + entry.getKey() + " 값: " + entry.getValue());
}
// Entry 객체를 활용한 값 읽기
Map.Entry<Integer, String> entry = null;
entry = treeMap.firstEntry();
System.out.println("키: " + entry.getKey() + " 값: " + entry.getValue());
entry = treeMap.lastEntry();
System.out.println("키: " + entry.getKey() + " 값: " + entry.getValue());
entry = treeMap.higherEntry(5);
System.out.println("키: " + entry.getKey() + " 값: " + entry.getValue());
entry = treeMap.lowerEntry(6);
System.out.println("키: " + entry.getKey() + " 값: " + entry.getValue());
// 전체 객체 삭제
treeMap.clear();
}
}
출처: https://ittrue.tistory.com/154 [IT is True:티스토리]
1-13. Properties
HashMap의 구버전인 Hashtable을 상속받아 구현
Hashtable은 키와 값을 (Object,Object)로 저장, Properties는 키와 값을 (String, String)으로 저장
1-14. Collections
Arrays가 배열과 관련된 메서드들을 제공하는 것처럼 Collections는 컬렉션과 관련된 메서드를 제공.
컬렉션의 동기화
멀티 쓰레드 프로그래밍에서는 하나의 객체를 여러 쓰레드가 동시에 접근할 수 있기 때문에
데이터의 일관성을 유지하기 위해서는 공유되는 객체에 동기화가 필요하다.
public static <T> Set<T> synchronizedSet(Set<T> s)
public static <T> List<T> synchronizedList(List<T> list)
public static <K, V> Map<K, V> synchronizedMap(Map<K, V> m)
public static <T> Collection<T> synchronizedCollection(Collection<T> c)
변경불가 컬렉션 만들기
컬렉션에 저장된 데이터를 보호하기 위해, 읽기 전용으로 만들어야 하는 경우
static Collection unmodifiableColection(Collection c)
static List unmodifiableList(List list)
static Set unmodifiableSet(Set s)
static Map unmodifiableMap(Map m)
static NavigableSet unmodifiableNavigableSet(Nvigable s)
static SortedSet unmodifiableSortedSet(Sorted s)
static NavigableMap unmodifiableNavigableMap(NavigableMap m)
static SortedMap unmodifiableSortedMAp(SortedMap m)
싱글톤 컬렉션 만들기
단 하나의 객체만 저장하는 컬렉션
static List singletonList(Object o)
static Set singleton(Object o) // singletonSet이 아님
static Map singletonMap(Object key, Obect value)
한 종류의 객체만 저장하는 컬렉션 만들기
컬렉션은 모든 종류의 객체를 저장할 수 있다는 특징이 있다.
지정된 종류의 객체만 저장할 수 있도록 제한하고 싶을 때 다음 메서드를 사용한다.
=> 지네릭스를 사용해 간단히 처리 가능
tatic Collection checkedCollection(Collection c, Class type)
static List checkedList(List list, Class type)
static Set checkedSet(Set s, Class type)
static Map checkedMap(Map m, Class keyType, class valueType)
static Queue checkedQueue(Queue queue, Class type)
static NavigableSet checkedNavigableSet(NavigableSet s, Class Type)
static SortedSet checkedSortedSet(SortedSet s, Class type)
static NavigableMap checkedNavigableMap(NavigableMap m , Class keyType, class valueType)
static SortedMap checkedSortedMap(SortedMap m, Class keyType, class valueType)
// 예시
List list = new ArrayList();
List checkedList = checkedList(list, String.class);
checkedList.add("abc");
checkedList.add(new Integer(3)); // ClassCastException 발생'백엔드' 카테고리의 다른 글
| [JAVA의 정석] Chapter13 (1) | 2024.09.08 |
|---|---|
| [JAVA의 정석] Chapter12 (1) | 2024.09.08 |
| [JAVA의 정석] Chapter10 (0) | 2024.09.08 |
| [JAVA의 정석] Chapter08 - 09 (1) | 2024.09.08 |
| [JAVA의 정석] Chapter07 (2) | 2024.09.08 |



